Здравствуйте, уважаемые читатели. Я продолжаю свою серию постов про распределенную
систему контроля версий Mercurial. В этой статье мы подробно поговорим об основных
приемах организации ветвлений в Mercurial. В
предыдущей статье мы рассмотрели "спонтанное" ветвление, возникающее в случае наличия
в репозитории разных линий ревизий от разных разработчиков, хотя каждый из них работает
в основной ветви разработки, в этой статье мы рассмотрим работу с ветвлениями, вызванную
осознанной необходимостью разделения линий разработки. Также в этой статье я буду
указывать какие преимущества и недостатки имеются у обсуждаемых способов организации
ветвей. Указанные преимущества и недостатки являются моим личным мнением, и вполне
могут не совпадать с вашим.
Для начала дадим определения ветви, чтобы начинать с единого понимания процесса.
Обратившись к wiki меркуриала я нашел определение, которое мне кажется вполне корректным:
ветвь (branch) - это связанная последовательность ревизий (changeset) являющаяся
отдельным направлением разработки. Таким образом, ветвь - это в первую очередь логическое
понятие, так как в случае с распределенными системами контроля версий она будет
содержать значительное число "спонтанных" ветвлений-слияний.

Рисунок 1. Исходное состояние репозитория

Рисунок 2. Новая анонимная ветвь в репозитории
В этой статье продолжим работу над нашим примером. На рисунке показано состояние
нашего репозитория после операций с ним в предыдущих частях цикла. И хотя формально
в репозитории уже имеется одно ветвление, Mercurial нам говорит что ветвь одна:
$ hg branches
default 4:6d6c634e2e20
Команда hg branches выводит список всех именованных ветвей в репозитории.
Как мы видим основная ветвь разработки называется default. Если быть точным, так
называется ветвь в которую происходит первый коммит в репозиторий, так сказать название
по умолчанию. На рисунке 1 приведено текущее состояние репозитория и граф ревизий
в нем находящихся. Я буду красным кружком отмечать "вершину" (tip) репозитория,
как сказано в документации Mecurial, вершина - это самая свежая ревизия в репозитории.
Команда hg branches не выводит анонимные ветви, хотя разработчики могут их
использовать при необходимости, и создавать самостоятельно.
Анонимное ветвление
На самом деле, создание ветви при работе с Mercurial не является чем-то из ряда
вон выходящим, для распределенной модели контроля версий это стандартная операция,
и поэтому может быть произведена крайне просто, фактически, простым коммитом. То
есть мы должны привести рабочую копию в состояние отличное от "вершины" (tip), внести
изменения и выполнить коммит. Ничего больше. Для этого локальную копию исходного
кода вернем в состояние ревизии 2:66c5686e355e:
$ hg update -r 66c5
0 files updated, 0 files merged, 1 files removed, 0 files unresolved
$ ls -l
-rw-r--r-- 1 mike mike 22 2010-01-07 22:22 first.txt
-rw-r--r-- 1 mike mike 61 2009-11-27 11:15 other.txt
-rw-r--r-- 1 mike mike 57 2009-11-27 00:03 readme.txt
После этого создадим в локальной копии файл branch.txt, добавим его в репозиторий
и выполним коммит:
$ ls -l
-rw-r--r-- 1 mike mike 61 2010-01-31 18:55 branch.txt
-rw-r--r-- 1 mike mike 22 2010-01-07 22:22 first.txt
-rw-r--r-- 1 mike mike 61 2009-11-27 11:15 other.txt
-rw-r--r-- 1 mike mike 57 2009-11-27 00:03 readme.txt
$ hg add
adding branch.txt
$ hg commit
created new head
$ hg branches
default 5:ff8ffd5270cb
И Mercurial нам честно сообщает что создал новую "голову". На рисунке 2 показано
текущее состояние репозитория. Отмечу два момента: во-первых, ветвь default осталась
на своем месте, и теперь заканчивается ревизией 5:ff8ffd5270cb, то есть "вершиной"
(tip); а во-вторых все эти ветвления находятся локально в нашем репозитории. Локальность
производимых ветвлений - это главное, коренное, отличие от централизованных систем
контроля версий, в том числе от Subversion. Никто не увидит вашей ветви до тех пор
пока вы не синхронизируете свой репозиторий с удаленным (обычно командой push).
С другой стороны выполнение pull приведет к появлению в вашем репозитории
всех ветвей, имеющихся в удаленном.
Преимущества
Основным преимуществом этого способа является крайняя простота. Не нужно ничего
придумывать, выполнять сложных операций, оповещать других участников команды - просто
апдейт и коммит.
Недостатки
Недостатки вытекают из анонимности ветви. Фактически, понять, что у вас есть
ветвь разработки, исходя из вывода стандартных операций Mercurial, затруднительно.
Особенно после 2-3 месяцев активной работы с репозиторием, когда количество таких
мелких ветвлений приближается к сотне. Соответственно вам придется писать информативные
подписи к коммитам, если анонимные ветви предполагается использовать в дальнейшем.
Для переключения между ветвями разработки вам придется использовать номер ревизии,
который, как известно, простой хэш - очень удобен для машины, но крайне неудобен
для человека.
Таким образом, анонимные ветви - это отличный механизм для внесения быстрых (по
количеству ревизий) исправлений, логически сильно связанных с направлением основной
ветви разработки, то есть для организации ветвления на 2-3 ревизии с последующим
слиянием с основной ветвью. Для организации больших ветвей, логически необходимых
для разделения направлений разработки следует использовать именованные ветви.
Именованное ветвление
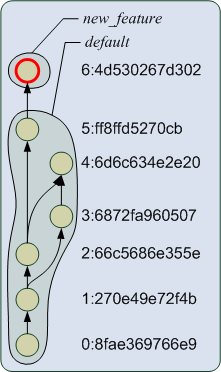
Рисунок 3. Именованные ветви в репозитории
Вполне естественно, что в Mercurial предусмотрен способ создания ветвей разработки
с некоторыми именами, задаваемыми пользователем. Для организации подобных ветвлений
предназначена команда hg branch. С помощью этой команды версия, находящаяся
в локальной копии помечается ветвью с новым именем, при этом сама ветвь будет создана
только после того, как вы выполните коммит. Попробуем сейчас сделать именованную
ветвь, родительской ревизией для которой будет ff8f:
$ hg branch new_feature
marked working directory as branch new_feature
$ hg commit
$ hg branches
new_feature 6:4d530267d302
default 5:ff8ffd5270cb
Итак мы видим, что Mercurial уже знает про две именованные ветви, "вершинами"
для которых являются ревизии ff8f и 4d53, хотя на графе ревизий это одна ветвь.
На рисунке 3 я показал, что именно понимается под именованной ветвью в Mercurial,
при этом, фактически, для каждой ветви есть своя "вершина" (tip), хотя hg log
это не показывает (я приведу только смысловой отрывок):
$ hg log
changeset: 6:4d530267d302
branch: new_feature
tag: tip
user: mike@mike-vbox
date: Sun Jan 31 21:31:07 2010 +0300
summary: Создаие именованной ветви в репозитории
changeset: 5:ff8ffd5270cb
parent: 2:66c5686e355e
user: mike@mike-vbox
date: Sun Jan 31 18:56:23 2010 +0300
summary: Создание анонимной ветви
changeset: 4:6d6c634e2e20
parent: 3:6872fa960507
parent: 2:66c5686e355e
user: mike@mike-vbox
date: Sun Jan 10 20:34:21 2010 +0300
summary: Выполнен мерж двух веток
changeset: 3:6872fa960507
parent: 1:270e49e72f4b
user: mike@mike-vbox
date: Sun Jan 10 19:40:45 2010 +0300
summary: Файл second.txt создан во втором репозитории
Убедиться в том, что "вершины" все таки существуют можно с помощью hg update,
то есть переключившись на другую ветвь:
$ hg update default
0 files updated, 0 files merged, 0 files removed, 0 files unresolved
$ hg ident
ff8ffd5270cb
А затем переключится обратно:
$ hg update new_feature
0 files updated, 0 files merged, 0 files removed, 0 files unresolved
$ hg ident
4d530267d302 (new_feature) tip
При этом в нашем репозитории сложилась интересная ситуация. tip ветви default
не совпадает с "головой" (head) этой же ветви. В этом легко убедиться попросив Mercurial
сказать какие же "головы" в нашем репозитории:
$ hg heads
changeset: 6:4d530267d302
branch: new_feature
tag: tip
user: mike@mike-vbox
date: Sun Jan 31 21:31:07 2010 +0300
summary: Создаие именованной ветви в репозитории
changeset: 4:6d6c634e2e20
parent: 3:6872fa960507
parent: 2:66c5686e355e
user: mike@mike-vbox
date: Sun Jan 10 20:34:21 2010 +0300
summary: Выполнен мерж двух веток
Отмечу лишь один очень важный факт - ветвление произведено в вашем локальном
репозитории, и вы можете работать с ним так, как вам угодно, при этом вы не боитесь
поломать чужой код своим коммитом, или вызвать у тимлида приступ головной боли своими
ветвлениями. Вот именно так концепция распределенной системы контроля версий позволяет
решить стандартные болячки централизованных систем.
Преимущества
Итак именованное ветвление лишь немногим сложнее анонимного, однако позволяет
организовать работу над сложным проектом с несколькими направлениями разработки
наиболее эффективным образом. Имя ветви является метаданными каждой ревизии, что
позволяет корректно отслеживать изменения, произошедшие в проекте. Хотя принципиальных
отличий от анонимных ветвей, на самом деле, нет.
Недостатки
К недостаткам, в некоторой степени, можно отнести синдром разрастания ветвей.
То есть, если вы будете использовать именованные ветви при каждой необходимости
отпочковаться от основной, вывод команды hg branches будет просто гиганским
через некоторое время. Хотя ветви можно закрывать при коммитах (опция --close-branch),
не стоит делать именованные ветви там где они не нужны.
Ветвление в клонах репозитория
Последний способ организации ветвления о котором я расскажу - ветвление в клонах.
На самом деле способ очевиден, и вытекает из третьей части этого цикла. Ничто не
мешает пользователю лично создать клон репозитория и в нем вести отдельную ветвь
разработки. Таким образом, для каждой ветви потребуется отдельный репозиторий. Безусловно
модель распределенной системы контроля версий Mercurial позволяет подобную трактовку
ветвления разработки, однако рассмотрим аспекты подобного подхода:
Преимущества
Немного более безопаснее чем при других способах. На самом деле в данном случае
способ выстрелить себе в ногу только один - запушить что нибудь этакое в удаленный
репозиторий, тогда как при локальном ветвлении способов выстрелить себе в ногу немного
больше.
Недостатки
На мой взгляд недостатки перевешивают все преимущества. Самый главный недостаток
- при каждом клонировании вам придется вытягивать весь репозиторий, то есть, если
вам захотелось получить доступ к некоторой ветви вам придется вытянуть весь репозиторий
относящийся к этой ветви, и так для каждой. Второй недостаток - бекапить вам придется
не один репозиторий, а несколько. Что не логично.
На этом я заканчиваю рассматривать ветвления в Mercurial. Думаю следующая статья
будет посвящена способам слияния ветвей, а также сложным моментам при слиянии, при
упоминании которых у пользователей Subversion резко падает давление и начинают трястись
руки. :)
Уважаемые читатели. Просьба комментировать посты. Возможно я упустил какие-то
моменты, требующие разъяснения, о которых стоило бы написать.




